[

](https://substackcdn.com/image/fetch/$s_!jW37!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F067fc7d3-71c3-4bad-94d4-7928c030ad40_1456x816.png)
Your brand just disappeared. Not from Google-you can still see it there, ranking fifth for “project management software,” same as last month. Not from social media, where your engagement metrics look fine. Your brand disappeared from somewhere else, somewhere you didn’t know to look.
It vanished inside ChatGPT.
Last quarter, fifty-eight percent of your target demographic used generative AI tools for product recommendations. When they asked “What’s the best project management tool for a remote team?”, the model gave them five names. Yours wasn’t one of them. Your competitor-the one you’ve been outspending on Google Ads for three years-was listed first. The model called them “intuitive and well-suited for distributed teams.” It called your product... nothing. Because it never mentioned you at all.
You discover this on a Tuesday afternoon when your VP of Sales forwards you a Slack message from a lost deal. The prospect said they “did their research” and decided to go with the competitor. When your sales team asked what research, the prospect said: “I asked ChatGPT.”
This is happening to thousands of brands right now. The infrastructure of product discovery has shifted underneath them, and most don’t have instruments to measure it.
The Mediation Layer
The statistics arrived gradually, then suddenly. In January 2025, thirty-eight percent of U.S. consumers reported using generative AI for online shopping. By July, that number had climbed to fifty-nine percent. The monthly growth rate was running at thirty-five percent-not thirty-five percent annually, thirty-five percent in nine months.
The demographic stratification told its own story. Among consumers aged eighteen to twenty-nine, seventy-nine percent had used AI tools for purchase decisions. Among those aged sixty-five and older, the rate was fifteen percent. But the older cohort was growing faster. Between September 2024 and February 2025, Baby Boomer adoption increased sixty-three percent. The skeptics were converting.
The commercial intent metrics were even more striking. Traffic from AI referrals generated eighty percent more revenue per visit than traditional search traffic. Conversion rates from AI-sourced visitors ran twenty to thirty percent higher than organic search benchmarks. Bounce rates were forty-five percent lower. These weren’t browsing sessions. These were deliberate, high-intent research missions that terminated in purchase decisions.
But here’s the anomaly that should worry you: OpenAI’s internal analysis of 1.5 million ChatGPT conversations revealed that only 2.1 percent of queries were shopping-related. A tiny sliver of total usage. Yet that tiny sliver was driving a tenfold year-over-year increase in AI referral traffic to retail sites.
The mathematics of attention had changed. Traditional search might expose a user to ten brands across three pages of results. An LLM conversation typically surfaces three to five brands in a single synthesized answer. The competition compressed. The stakes increased.[
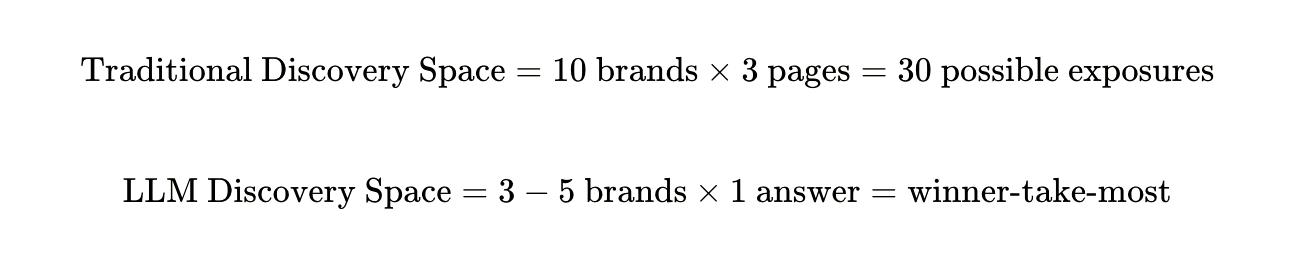
](https://substackcdn.com/image/fetch/$s_!5X4T!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7f64b0ce-556a-4cfd-a6b8-287edc64eff5_1310x254.png)
If you’re not in that answer, you don’t exist.
The Instrumentation Problem
You can’t manage what you can’t measure. The first generation of brand managers operating in the LLM era had no dashboards, no analytics, no way to know whether ChatGPT was recommending them or burying them. They were running marketing campaigns optimized for a discovery mechanism-search engines, display ads, influencer partnerships-that an increasing percentage of their audience had abandoned.
The monitoring tools emerged in 2024 and 2025, built by founders who recognized the instrumentation vacuum. The market bifurcated quickly into tiers distinguished by sophistication, coverage, and price.
The Entry Tier: Visibility
The cheapest tools start at around ninety euros per month. Peec AI, founded in 2025 and backed by twenty-one million euros in Series A funding, offers a straightforward value proposition: they’ll run your prompts through ChatGPT, Perplexity, and Google AI Overviews daily. You define the questions your customers ask-”best CRM for startups,” “top email marketing platforms,” “project management tools with Slack integration”-and Peec tells you whether your brand appeared, how often, and in what context.
The workflow is simple. You get a share-of-voice percentage. If your competitor is mentioned in forty-seven percent of relevant queries and you’re mentioned in twelve percent, you know you have a problem. You don’t necessarily know how to fix it, but at least you can see the battlefield.
These tools serve a specific function: they surface the previously invisible. For a growing company with limited budget-say, a Series A SaaS startup with a twenty-person marketing team-knowing you’re being systematically excluded from AI recommendations is actionable intelligence even if the tool doesn’t tell you why.
The limitation is representativeness. When you input prompts, you’re choosing which questions to monitor. Are those the questions your actual customers ask? Or are they the questions you think they ask? The tool can only show you what you think to measure.
The Professional Tier: Attribution
As you move up-market, the tools become more sophisticated. Platforms like Profound, which start at around five hundred dollars per month and scale to thousands for enterprise accounts, promise something closer to causal understanding.
Profound’s differentiation comes from its data source. Instead of running synthetic prompts through LLM APIs, it claims to analyze four hundred million real human-to-AI conversations. This “demand-side” view theoretically shows you what users are actually asking, not what you assumed they’d ask.
The platform integrates with Google Analytics 4, attempting to solve the attribution nightmare that has plagued marketers since LLMs started driving traffic. When someone clicks through from a ChatGPT recommendation, traditional analytics often classify it as “direct” traffic because the referrer is obscured. Profound’s integration aims to tag these sessions correctly, allowing you to calculate:[

](https://substackcdn.com/image/fetch/$s_!lu73!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd5a0a395-3e0e-4aa7-a6d9-20541a211887_1326x168.png)
The company published a case study claiming that Ramp, a corporate card startup, achieved a seven-times increase in AI brand mentions within ninety days using Profound’s optimization recommendations. The case study reported “measurable revenue growth” but didn’t disclose the actual dollar figures.
This is characteristic of the validation problem across the industry. Almost every tool publishes impressive-sounding statistics-”287% ROI in first quarter,” “25x higher conversion from AI traffic”-but the methodologies are rarely peer-reviewed and the customer examples are often anonymized. You’re asked to trust the numbers without seeing the experimental design.
The Integration Tier: Unified Visibility
For brands already paying for comprehensive SEO platforms, the calculus shifts toward integration. Semrush, one of the dominant SEO tool suites, added AI visibility tracking as a module accessible to existing subscribers. Their advantage is structural: they already have a database of one hundred thirty million prompts across eight geographic regions, drawn from years of search keyword research.
When you’re a Semrush customer, you can import your existing SEO keyword list and instantly see how those same terms perform when tested as conversational prompts in ChatGPT, Gemini, and Perplexity. You don’t need to build a new workflow or learn a new dashboard. The AI visibility data sits alongside your organic rankings and paid search performance.
The drawback is cost. Semrush subscriptions start around one hundred thirty dollars per month for basic access, and AI features are typically gated behind higher tiers. For a small brand with limited budget, you’re paying for an enterprise suite to access one feature.
The Methodological Divide
The reliability of any LLM monitoring tool depends on a technical distinction most buyers don’t think to ask about: How does the tool actually query the model?
There are two fundamental approaches, and they produce different results.
API Access: Some tools query LLMs through their application programming interfaces. You send a structured request to GPT-4’s API, it returns a text response. This is fast, cheap, and scalable. But research has documented that API responses differ from what users see in the public ChatGPT interface. The overlap is approximately thirty-eight percent. API responses often omit citations, source links, and the “retrieval-augmented” content that appears when a real human uses the web-based version.
If you’re monitoring via API, you might be blind to exactly the feature that drives trust: the cited sources. Users don’t trust ChatGPT’s raw output. They trust it when it says “According to Wirecutter...” and provides a clickable link.
UI Crawling: The more expensive tools simulate actual user sessions. They open Chrome, navigate to chat.openai.com, type the query as a human would, and scrape the full response including all citations and formatting. This captures what your customer sees.
The cost differential is significant. API calls cost fractions of a cent. UI simulation requires headless browsers, proxy rotation to avoid rate limiting, and significantly more infrastructure. Tools that crawl UIs typically charge premium prices to cover these costs.
You’re buying a choice between cheap-but-potentially-misleading and expensive-but-accurate. Most tools don’t disclose which method they use. You have to infer from their feature descriptions and pricing. If a platform offers “unlimited prompts” for thirty dollars per month, they’re almost certainly using APIs. If they charge three hundred dollars for three hundred fifty prompts, they’re likely doing UI simulation.
The Demographic Blind Spot
Now imagine you run marketing for a laptop brand. Your product line spans from three-hundred-dollar Chromebooks to three-thousand-dollar workstations. Your customer segments have radically different needs: college students prioritize price, video editors prioritize GPU performance, corporate buyers prioritize security and vendor support.
You pay for an LLM monitoring tool. You input the prompt: “What’s the best laptop for video editing?” The tool runs this exact phrase through ChatGPT daily and reports your visibility percentage. Let’s say you’re mentioned forty percent of the time. Good news, apparently.
But here’s what you don’t know: Does ChatGPT recommend your three-thousand-dollar workstation to the professional editor and your three-hundred-dollar Chromebook to the student? Or does it conflate your entire product line into a generic “Laptop Brand X” and recommend based on aggregate reputation?
The reality is more complex. LLMs condition their responses based on implicit signals in the user’s query. A prompt phrased as “I need a laptop for editing 4K footage in Premiere Pro” triggers technical depth-the model infers professional user, emphasizes GPU specs, and tends to recommend higher-tier products. A prompt phrased as “What laptop should I get for school?” triggers budget sensitivity-the model infers student user, emphasizes battery life and portability, and trends toward lower-price options.
Your monitoring tool, testing one generic prompt, captures neither of these nuances.
Only one platform-Profound-explicitly offers “persona-based query building.” Their tier structure allows you to define three to seven personas depending on your subscription level. But even here, the methodology disclosure is thin. How do they construct personas? What attributes do they vary? How do they phrase queries to simulate demographic differences?
The gap is this: the market has monitoring tools that tell you “what the model says,” but lacks tools that tell you “what the model says to whom.”
The Verification Paradox
The fundamental challenge with LLM monitoring is that you’re measuring a moving target through a black box.
Traditional SEO operates in a relatively stable environment. Google’s algorithm changes, but the structure is consistent: there are ten blue links, ranked by some combination of relevance and authority signals. You can test whether changing your meta description improves click-through. You can A/B test whether adding schema markup increases visibility. The feedback loop is measurable.
LLM recommendations are non-deterministic. Ask ChatGPT the same question five times, you might get five different answers. The model has a temperature parameter that introduces randomness. Some tools-like Mangools AI Search Watcher-address this by running each prompt five times and averaging the results. Others run it once and report that snapshot as definitive.
Beyond randomness, there’s version drift. When OpenAI updates GPT-4 to GPT-4.5 or introduces a new training data cutoff, the model’s “knowledge” about your brand could change overnight. A competitor who published aggressive SEO content in the last three months might suddenly appear in more recommendations because the model’s recency bias shifted. Tools that don’t account for version changes might attribute this shift to your own actions-or fail to notice it entirely.
Then there’s the opacity problem. You can see that your visibility percentage dropped from forty-seven percent to thirty-one percent over two weeks. Why? Did a competitor publish better content? Did your website go down and the model couldn’t retrieve current information? Did OpenAI change how it weights sources? You’re staring at an effect without access to the cause.
The ROI Question Nobody Can Answer
The marketing deck from every LLM monitoring platform includes impressive statistics. “AI-referred visitors convert at twenty-five times the rate of traditional search visitors.” “Brands appearing in AI citations see fifty to sixty percent reduction in customer acquisition costs.” “287% to 415% return on investment in the first quarter post-implementation.”
These numbers come from case studies. The case studies come from the tool vendors themselves, describing their own customers. The customers are typically anonymized. The methodologies are rarely disclosed in detail. The timelines are always suspiciously tight-ninety to one hundred twenty days from implementation to “measurable results.”
You should be skeptical.
Here’s what we know with higher confidence: Adobe’s analysis of multiple industries found that AI referral traffic generates eighty percent higher revenue per visit compared to non-AI traffic. This data comes from analyzing actual clickstream and conversion data across Adobe’s customer base, not from a single cherry-picked success story. The sample size is large enough to be credible.
But that eighty percent figure is an average. It doesn’t tell you whether improving your LLM visibility from thirty percent to fifty percent will actually drive proportional revenue growth. The causal chain has gaps:[

](https://substackcdn.com/image/fetch/$s_!8jOh!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb56d95a6-5b44-445e-bbf4-244198dceec5_1302x136.png)
Tools can measure the first arrow (did your share-of-voice increase?). Analytics platforms can measure the third arrow (did AI traffic increase?). Nobody has published research definitively linking the first to the third while controlling for confounds.
The honest assessment: LLM monitoring tools measure intermediate outcomes (visibility, share-of-voice) that are plausibly but not provenly connected to business outcomes (revenue, market share). You’re buying a proxy metric and hoping it predicts what you actually care about.
The Demographics of Trust
The divide isn’t just generational. It’s about who’s been trained to question algorithmic outputs versus who accepts them as authoritative.
Seventy-nine percent of eighteen-to-twenty-four-year-olds use AI for shopping decisions. But their trust isn’t blind. Among Gen Z users specifically, sixty-one percent report using AI tools to help with purchases, yet only fourteen percent of all AI users say they trust the information “completely.” The modal behavior is trust-with-verification: get the AI recommendation, then cross-check with human reviews or expert sources.
The gender gap persists at nine percentage points. Fifty-two percent of men use AI for purchase decisions versus forty-three percent of women. The trust differential maps to different concerns: fifty-seven percent of men worry about inaccurate recommendations (the model being factually wrong), while thirty-six percent of women prioritize transaction security (the model being unsafe). These aren’t the same fear. They require different reassurances.
Income stratifies the market more than age. Among households earning over one hundred twenty-five thousand dollars annually, sixty-five percent use LLMs for shopping and fifty-two percent use them daily. Among households under fifty thousand, usage drops to fifty-three percent with only twenty percent daily frequency. The wealthy use AI as a research tool. Everyone else uses it occasionally, often for specific high-consideration purchases where the stakes justify the effort.
What you’re seeing in these numbers is the formation of a “search divide” that mirrors the digital divide of the early internet. The professionals, the educated, the financially secure-they’ve already migrated to AI-mediated discovery. They’re the ones asking sophisticated queries like “compare the GPU performance of these three laptops for machine learning workloads.” Your brand needs to show up in those answers because that’s where the high-value customers are shopping.
The mass market is coming next, but they’re not there yet. If your brand strategy assumes universal LLM adoption, you’re overindexed on early adopters and missing the seventy percent who still start with Google.
What the Tools Can’t Tell You
The current generation of LLM monitoring platforms excels at description but fails at prediction.
They can tell you: “Your brand was mentioned in thirty-eight percent of prompts we tested this week.”
They cannot tell you: “If you increase that to fifty percent, you’ll gain 3.2 million dollars in annual revenue.”
They can tell you: “Your competitor’s share-of-voice increased by twelve points.”
They cannot tell you: “This change was caused by their content strategy versus randomness in the model’s outputs.”
They can tell you: “ChatGPT describes your product as ‘reliable but expensive.’”
They cannot tell you: “This framing is why you’re losing deals to cheaper competitors” versus “customers who value reliability are converting well from this framing.”
The gap between visibility metrics and business outcomes creates a verification problem. Consider the following scenario, labeled clearly as hypothetical to illustrate the challenge:
Hypothetically, your optimization efforts increase your LLM visibility from thirty percent to sixty percent over three months. Your LLM monitoring tool celebrates this as success. But your revenue from new customers stays flat. What happened?
Possibility One: The AI traffic didn’t convert because the visitors were low-intent browsers.
Possibility Two: The AI directed traffic to the wrong product page (your budget option instead of your premium option).
Possibility Three: Your visibility increased, but for queries that don’t drive purchases (”what is project management?” versus “best project management tool to buy”).
Possibility Four: Your visibility increased, but competitors’ visibility increased more, and the market expanded rather than shifted.
Without integrated analytics connecting LLM metrics to actual revenue data-something only a few platforms attempt-you can’t distinguish between these explanations. You’re optimizing for a metric that might or might not predict the outcome you care about.
The Survey Calibration Nobody’s Doing
Here’s the integration that’s missing from every platform currently available: the connection between what customers actually want (measured via surveys or customer satisfaction data) and what LLMs recommend.
Consider two competing brands in the wireless headphone market:
Brand Ahas exceptional noise cancellation and mediocre battery life. Customer surveys reveal that their buyers prioritize audio quality and are willing to tolerate shorter battery in exchange.
Brand Bhas good battery life and acceptable noise cancellation. Their customers value all-day use.
Now you test LLM recommendations. ChatGPT consistently emphasizes battery life as a key differentiator. When users ask for headphone recommendations, the model mentions Brand B more frequently because “battery life” is easier to extract from specs and appears more prominently in reviews.
Brand A’s actual competitive advantage-the subjective quality of noise cancellation that survey respondents praise but don’t quantify precisely-is underweighted in the LLM’s synthesis. Not because the model is wrong, but because the attribute is harder to score definitively from text sources.
Brand A could optimize their content to emphasize battery life. This might increase their LLM visibility. But it would be optimizing for an attribute their actual customers don’t prioritize. Short-term visibility gain, long-term brand confusion.
The correct optimization would be: measure what your customers privately value (survey), then amplify those attributes in LLM-accessible formats (structured content, authoritative reviews, FAQ pages). The monitoring tool shows whether the optimization worked. The survey data tells you whether you optimized for the right thing.
No current platform offers this integration. They monitor LLM outputs. They don’t validate whether those outputs align with customer preferences measured through traditional research methods.
The Persona Testing That Doesn’t Exist
Return to your laptop brand with product lines spanning students to professionals. The question you need answered: “Do different demographic segments get different recommendations from the same LLM?”
Most monitoring tools can’t tell you. They test prompts like “best laptop for video editing” without conditioning those prompts on user signals. But real users embed demographic markers in their queries:
A student might ask: “I need a laptop for college that won’t break the bank.”
A professional might ask: “What’s the best mobile workstation for 4K editing with color grading?”
The language differs. The implied constraints differ. The model’s response should differ. Does it?
One way to test this would be to generate one thousand synthetic personas spanning your actual customer demographics-age, income, expertise level, use case-and run product recommendation queries phrased as each persona would phrase them. Then analyze: Which brands appear for which personas? Are you winning with students but losing with professionals? Does the model recommend your budget line to high-income users who should be seeing your premium line?
This is technically feasible. The synthetic persona methodology exists. Large language models can be conditioned to generate queries in different demographic voices. But scanning the feature lists of the fifteen-plus monitoring platforms currently available, only one or two mention persona-based testing, and their disclosure of how they implement it is minimal.
The gap exists because it’s operationally complex. Running one prompt across five LLMs is straightforward. Running one thousand variants of that prompt, each conditioned on a different persona, requires automation infrastructure that most platforms haven’t built.
But the value is potentially enormous. If you discover that ChatGPT systematically recommends your competitor to your highest-value demographic-say, CTOs of mid-market companies-you know exactly where to focus your optimization efforts. You need to appear in answers to queries phrased with technical sophistication and enterprise constraints. That’s a different content strategy than winning visibility with students or hobbyists.
The Market That’s Still Forming
The LLM monitoring industry is approximately eighteen months old. Peec AI was founded in 2025. Profound emerged in 2024. Even Semrush’s AI visibility features only launched in late 2024. These timelines mean we’re watching a market form in real-time, with all the instability that implies.
Funding signals suggest investors believe this is real. Peec raised twenty-one million euros in Series A. Multiple platforms have credible pricing structures and public customer testimonials. Gartner analysts are predicting a twenty-five percent drop in traditional search volume by 2026 specifically due to AI substitution.
But the consolidation hasn’t happened yet. There are too many tools with overlapping features and unclear differentiation. Some will fail. Some will merge. A few will become category leaders.
The safe bet for enterprise buyers is to default to existing SEO platforms adding AI modules-Semrush, BrightEdge-because even if the AI visibility market collapses, you still have your traditional search monitoring. The aggressive bet for fast-growing brands is to commit to AI-first platforms like Profound or Peec, accepting the risk of vendor instability in exchange for potentially superior AI-specific features.
The uncertainty matters because switching costs are high. Once you’ve built dashboards, trained your team on a specific platform’s interface, and integrated it with your analytics stack, migration is expensive. You’re making a bet on which vendor will still exist in three years.
What You’re Really Buying
Strip away the marketing language and the LLM monitoring value proposition reduces to this: you’re buying earlier warning of a problem you couldn’t see before.
The problem is that an increasing percentage of your audience is forming purchase intent in conversations with AI that you don’t control, can’t observe, and couldn’t influence until recently. The tools give you visibility. Some give you alerting when your position changes. A few give you guidance on what content to publish to improve your standing.
But they all share a fundamental limitation: they’re measuring second-order effects of a first-order phenomenon they can’t directly observe. They can’t see inside the LLM’s training data to know why it favors certain brands. They can’t predict how the next model update will shift recommendations. They can measure correlations but struggle to prove causation.
The honest value proposition is: “We’ll tell you whether you’re visible in AI recommendations, and roughly how you compare to competitors. Whether that visibility drives revenue, and whether optimizing for it is worth the cost, remains largely an act of faith.”
For some brands, that faith is justified. If you’re seeing ten-times traffic growth from AI referrals and those visitors are converting at eighty percent higher revenue-per-visit, spending a few thousand dollars monthly to monitor and optimize the channel makes strategic sense. The ROI doesn’t need to be proven to the third decimal place.
For other brands-those not yet seeing meaningful AI traffic, those serving demographics that haven’t adopted LLMs, those in categories where AI performs poorly-the tools are premature infrastructure. You’re paying to monitor a channel that doesn’t yet matter to your business.
The question you need to answer before buying any of these platforms is not “Can I afford this tool?” but rather “Can I afford to be blind to this channel?” The answer depends entirely on what percentage of your customers have already migrated their product discovery to conversations with machines.
And that percentage is changing every month.