The Textbook That Learns You
The machine watches you learn. You should watch it back.

You’re being watched.
Not by your teacher. Not by your classmates. By the textbook itself.
It tracks which sections you reread. Which questions you answer wrong. Which examples you skip. Then it rewrites itself. The vocabulary gets simpler. The examples change. The quizzes adapt. By the time you reach chapter three, you’re reading a different book than the student next to you.
This isn’t metaphor. This is Medhavi, Nolej, Clemson’s Virtual Teaching Assistant—intelligent textbook systems that combine artificial intelligence, semantic search, and real-time personalization to transform static materials into adaptive learning environments. Within minutes, they can generate fifteen different types of interactive activities: flashcards, crosswords, embedded quizzes, simulated conversations between an AI teacher and student, hierarchical mind maps.
The technology is real. The economics are more real.
Traditional course production costs between $25,000 and $150,000. It requires weeks of instructor time. AI-driven systems reduce video production from 24 hours to 3.75 hours per unit—costs dropping from $192 to $5.04. A sixfold efficiency gain. The math is not subtle: institutions under budget pressure do not need to be convinced. They need to be warned.
Because the question isn’t whether these systems will spread.
They will.
The question is what they are actually teaching.
The Architecture of Watching
Here is what happens when you open an intelligent textbook and type a question.
Your words become numbers. Not metaphorically—mathematically. The system runs your query through an embedding model, a neural network trained to convert language into coordinates in high-dimensional space. Semantically similar sentences end up geometrically close. “How does photosynthesis work?” and “What do plants do with sunlight?” end up near each other in that space, even though they share almost no words.
Your question-as-vector then gets compared to every chunk of the textbook, which has been similarly vectorized and stored in a database. The comparison uses cosine similarity—a formula that measures the angle between two vectors. Small angle means high similarity. The system retrieves the textbook passage most mathematically proximate to your question, feeds it to a language model, and synthesizes a response.
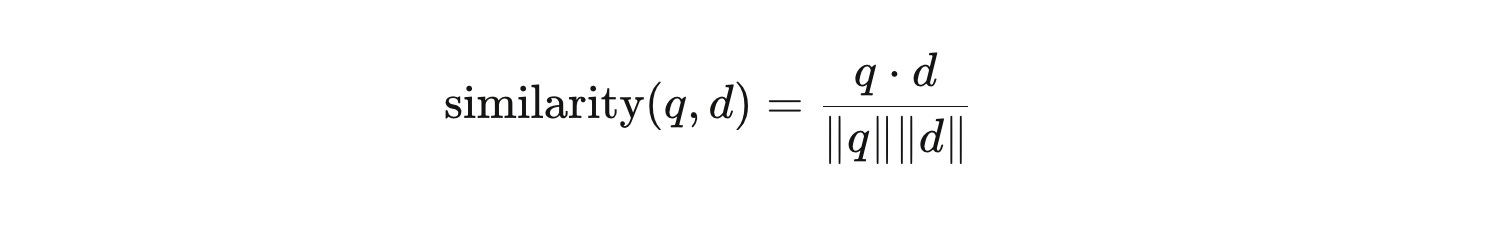
Elegant. Computationally precise.
Pedagogically incomplete.
Cosine similarity measures semantic overlap. It does not measure what you need to understand. If you ask why leaves change color in autumn and you are actually confused about energy transfer—not pigmentation—the system retrieves a technically correct passage about anthocyanins and leaves you more confused than before. The retrieval was accurate. The teaching failed.
This is the central tension in the architecture of intelligent textbooks: systems optimized for factual precision operating in environments that require conceptual diagnosis. RAG—Retrieval-Augmented Generation—prevents hallucination. It does not prevent irrelevance. The guardrails intercept requests for direct answers and rewrite them as scaffolded hints. The guardrails cannot identify when the scaffolding is built on the wrong foundation.
The system knows what words you used. It doesn’t know what you don’t understand.
The Factory
In six weeks, 40 designers at Lincoln Learning produced over 2,100 interactive videos. A task that would traditionally have taken years.
Consider what that number means. 2,100 videos. Six weeks. That is a pace of approximately 350 videos per week, 70 per day, assuming a five-day workweek. The content existed before AI. What AI compressed was the transformation pipeline: ingest the static resource, transcribe it, extract key concepts, generate interactive components, export for LMS deployment.
The results were not nothing. Students who used an AI coach after watching instructional videos showed 28% greater improvement than students who watched video alone. The effect size was 0.48—moderate by education research standards, but meaningful.
Here is what that number doesn’t tell you.
Human tutoring typically produces effect sizes between 0.7 and 1.0. The AI is better than passive video. It is not better than a skilled human.
Meanwhile, Polestar—an electric vehicle manufacturer—deployed Sana Labs’ intelligent learning platform and saw a 275% increase in active users. The press release presents this as evidence of learning. It is evidence of adoption. If Polestar migrated from a legacy system and mandated use, active users would increase regardless of educational value. The metric chosen reveals what was being measured: engagement, not mastery.
Nolej AI generates over 15 distinct activity types from 50 pages of text or 50 minutes of video—flashcards, crosswords, embedded quizzes, simulated dialogues, mind maps—all within minutes. Vendors cite 85% higher engagement and 75% better retention. Peer-reviewed validation of these figures is scarce.
A $5 video that fails to teach is more expensive than a $192 video that succeeds. The cost reduction is real. The educational value is asserted.
The Comfort Trap
Google’s “Learn Your Way” experiment transforms OpenStax textbooks into five formats: Immersive Text, Quizzes, Slides, Audio Lessons, Mind Maps. Students choose the modality that matches their current cognitive state. The system re-levels vocabulary and complexity to match their grade level and personal interests. A student interested in gaming sees physics through game mechanics. Another sees it through sports.
Pedagogical experts rated the experience 0.85 or higher on their criteria. Students who used personalized representations scored 11 percentage points higher on retention tests conducted three to five days after learning.
And then this: 100% of students reported feeling more comfortable taking assessments.
One hundred percent.
That number should stop you.
Comfortable is not the same as learning. Students who find material easier feel more comfortable. Students whose anxiety has been reduced feel more comfortable. Students who have been given content matched to what they already believe they know feel more comfortable. Comfort is an affective response. Learning is a cognitive gain. Conflating them is not a minor methodological error—it is a category mistake that shapes how we evaluate whether these systems work.
Personalization also requires categorization. Systems like AgentiveAIQ sort learners into archetypes: the Busy Manager gets podcasts, the Frontline Employee gets mobile videos, the Senior Expert gets dense documentation. The architecture assumes learners fit cleanly into profiles.
Suppose you are a software engineer who is expert in Python but a complete novice in machine learning. You are simultaneously expert and novice, depending on which question is asked. The system must oversimplify—treating you as one or the other—or multiply its personas into combinatorial complexity that becomes its own maintenance problem.
Some platforms generate synthetic learner profiles using language models when direct data is unavailable. These AI-invented profiles reportedly achieve 85% correlation with actual human responses. If a model can invent a fictional learner and match reality 85% of the time without interacting with a single human, human learning patterns are more predictable than we might want to admit. But the 15% gap matters. A system that miscategorizes a student who is struggling conceptually as merely “disengaged” provides motivational content when what the student needs is foundational repair.
You prefer the podcast. You need the workbook.
The Socratic Trap
Khanmigo refuses to give direct answers. The Clemson VTA refuses to give direct answers. The entire architecture of these systems is oriented toward the Socratic method: ask guiding questions, press students to explain their reasoning, make them construct the answer rather than receive it.
The intention is correct.
The outcome is more complicated.
Suppose you ask an AI tutor how to solve an integral. The AI asks: “What method would you try first?” You guess substitution. The AI says: “Good. Let’s walk through that.” You proceed step by step, the AI prompting each move. You reach the answer.
You never generated that solution independently. You navigated a guided scaffold. Whether you learned to solve integrals or learned to navigate AI scaffolding is not a distinction the system can make—and it is not a distinction the completion rate can measure.
Research on this is direct: unsupervised use of basic AI chatbots can erode long-term learning by encouraging what researchers call “shortcut-seeking behaviors.” Students in some studies scored up to 127% better than peers on immediate assessments while using AI. Their long-term retention suffered because the effortful processing required for durable memory never occurred.
The immediate score went up. The learning did not.
This is not a failure of the technology. It is a failure of the incentive structure in which the technology operates. Students have been trained by years of schooling to value correct answers over reasoning processes. Socratic AI designed for process-oriented learning encounters students optimized for outcome-oriented performance. The mismatch is not accidental. It is structural.
The AI reveals the problem. It did not create it.
The Integration Nightmare Nobody Mentions
Technical standards—LTI, Common Cartridge, API synchronization—are described in vendor materials as solved infrastructure. The implication: intelligent textbook systems plug into existing institutional ecosystems seamlessly.
They don’t.
LTI is a standard. Implementations vary. A tool that functions correctly in Canvas may fail in Blackboard due to subtle differences in how each platform interprets the standard. Common Cartridge export is supposed to preserve course structure. Canvas import routinely flattens hierarchies, strips custom HTML, breaks embedded scripts.
Advanced educators have developed what they call “Syllabus as Code” workflows to work around this. Treat course content as a single source maintained in Markdown, compile it into sanitized HTML using tools like Pandoc and Juice, paste the result into the LMS. This separates content from presentation, makes formatting immune to global LMS theme changes, and integrates with version control systems like Git.
It also requires comfort with command-line tools. For technically proficient instructors, this is elegant engineering. For everyone else, it is one more system to learn, one more dependency to maintain, one more point of failure when a package update breaks the generator at 11 PM before an 8 AM class.
Technical integration is never finished. APIs change. Platforms update. Vendor relationships shift. A system that works today may fail silently after a security patch six months from now. The maintenance burden is real, ongoing, and absent from every marketing document.
The Hardware Divide
On-device AI is the next announced phase. Microsoft and OpenStax have partnered to embed open educational resources into Copilot+ PCs. The argument: local processing enables access for students without consistent high-speed internet. Education becomes available in underserved communities.
The hardware required for the most advanced features—real-time tutoring, local RAG, multi-modal rendering—are Copilot+ PCs with specialized neural processing units delivering 40 or more Trillion Operations Per Second. The Acer Swift AI and HP OmniBook 7 represent this tier. Prices are declining. Some models reached $450 during promotional sales.
Equipping an entire school district at $450 per student is not a distribution problem. It is an infrastructure problem of the same scale as the inequity it promises to solve.
On-device AI is framed as an equity solution. It requires premium hardware. Students in low-income districts who currently lack reliable internet will not have these machines. The technology designed to close the gap may formalize it.
What We Are Actually Measuring
The evidence base for intelligent textbooks measures what is easy to measure.
Completion rates. User satisfaction. Short-term retention of factual knowledge. Production costs. Time savings. Active user counts.
None of these are learning. They are proxies for learning, and they are proxies that can be maximized independently of whether learning occurs. A system that makes students feel comfortable, increases their completion rate, reduces production costs, and leaves their capacity for independent reasoning unchanged has optimized every metric perfectly.
The metrics chosen reveal priorities. Speed and scale get measured because we value speed and scale. Learning gets described because we value learning. But when the evaluation comes, we measure what we can count.
Long-term retention—tested months after instruction, not days—is rarely studied. Transfer performance—can the student apply this knowledge to a novel problem in a different context—is almost never studied. Development of intellectual curiosity, tolerance for ambiguity, capacity for rigorous self-questioning: these are not in the data.
Can this continue? It can. Here is why it shouldn’t: the systems will spread, the metrics will be cited as evidence, and the actual question—are students learning to think—will remain unanswered while the infrastructure calcifies around the wrong measurements.
The Open Question
These systems are not frauds.
They reduce production costs. They handle routine questions. They provide instant feedback. They approximate tutoring for students who have no access to human tutors—and billions of students have no access to human tutors. A moderate effect size reaching millions of students is not nothing.
But the claims exceed the evidence. “Primary interface for 21st-century education” is a vendor assertion, not a research finding. The systems are better than static PDFs. They are not better than skilled human teachers. They are roughly equivalent to decent teachers under time pressure—and decent teachers under time pressure are not what we are trying to build toward.
The goal should be augmentation, not replacement. Automate the logistics—the routine questions, the scheduling, the basic feedback on factual recall. Free human instructors for the work that requires human capacity: diagnosing deep conceptual confusion, inspiring intellectual curiosity, modeling what rigorous thinking looks like in real time.
That requires honesty about what AI can and cannot do.
It can retrieve information. Generate quizzes. Approximate Socratic dialogue. Scale.
It cannot feel where a student is actually stuck. It cannot adjust in real time to confusion that the student hasn’t articulated yet. It cannot make a student fall in love with a subject.
The textbook is watching you.
You need to decide what you want it to learn.
Sources: Lincoln Learning / Creatium efficacy data; Google Learn Your Way study; Clemson VTA / NVIDIA RAG Blueprint documentation; Sana Labs Polestar case study; Edutopia research on AI and long-term learning; Khanmigo Michigan pilot data; CourseMagic / Common Cartridge integration documentation; Microsoft-OpenStax Copilot+ PC partnership.